The puzzle is to place eight queens on a chessboard so that no two queens attack each other. The problem is old and has been well studied, the Rosetta Code has solutions for more than 80 programming languages, SQL included.
However, the Rosetta’s SQL solution is implementing a recursive algorithm in SQL, as opposed to a relational approach. In this article I will use a relational design approach to the problem, and then translate that to SQL. The main idea is to design using natural language and concepts of domains, predicates, constraints, sets, set operations, and relations.
The logical design process is database agnostic; for the initial code samples I will use PostgreSQL, which can later be translated to other SQL dialects.
Domains
A domain is simply a set of all possible values over which a variable of interest may range.
The board is composed of 64 named squares, organised in eight rows and eight columns; rows and columns are labelled.
square_name = {'a1' .. 'h8'} -- set of square names
row_lbl = {'1' .. '8'} -- set of row labels
col_lbl = {'a' .. 'h'} -- set of column labels
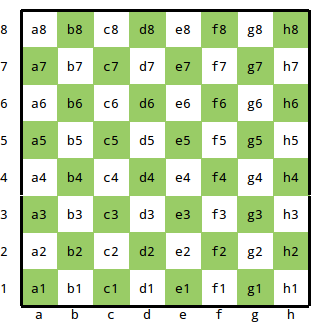
It is convenient to refer to a square by Continue reading “Eight Queens in SQL [1]”
